Oracle ADF is used to build large enterprise application. And if you want to have your application to run on high availabilty then you should understand what is High Availability (HA) .
What is High Availability –
High availability refers to the ability of users to access a system without loss of service. Deploying a high availability system minimizes the time when the system is down, or unavailable and maximizes the time when it is running, or available. This section provides an overview of high availability from a problem-solution perspective. With HA , even for new deployment you will never have down time.
Normally in large enterprise application , you don’t want your system to be down..Application deployed in cluster environment. If one of the server down then the user session should replicate to another cluster . Now , we have Oracle HTTP Server (OHS) or Apache plugin is to used to get single URL and manage internally to replicate the session and send request if one of cluster is fail.
How a web server handle request
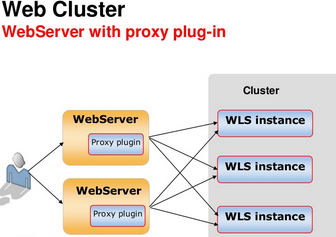
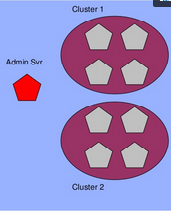
Cluster- Group of managed server running to provide scalability and reliability. In this multiple wls instance simultaneously and working together.Cluster is part of WLS domain . A domain can have multiple cluster
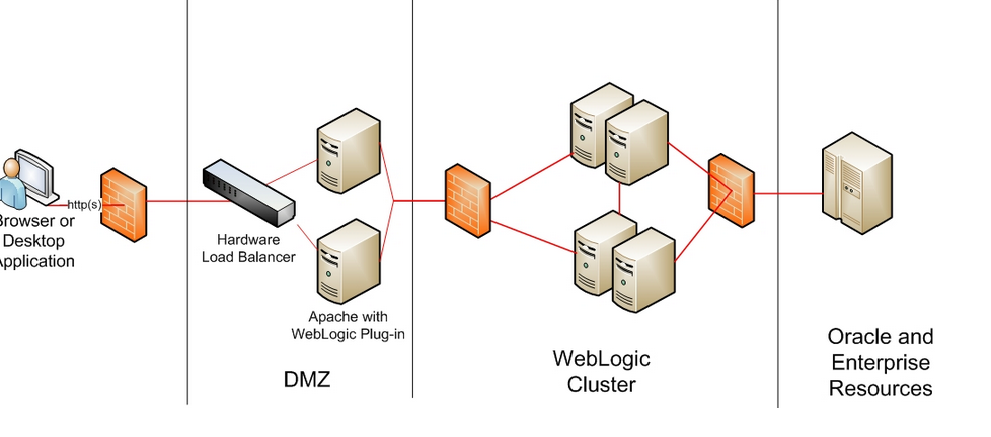
Architecture of Weblogic HA
Now the important point for developer – Few points designing and developing Oracle ADF application for HA.
There are 6 types of memory scopes. Read more on ADF memory scopes
When the Fusion web application runs in a clustered environment, a portion of the application’s state is serialized and copied to another server or a data store at the end of each request so that the state is available to other servers in the cluster.If it not serialized then user will lose data upon fail-over.
WebLogic duplicates those sessions by serializing the objects in the session and than transfers it to the secondary machine. Only the object that are stored in the session will be replicated. From an ADF perspective this means that managed bean with pageFlowScope and above will be replicated.It is very well defined in Oracle documentation and A-team article.
Configuring Oracle ADF development for High Availability
=> Changes in Application server-
While doing development Jdeveloper integrated server will not throw any errors by default. Add this parameter in server has to be run with the following JVM parameter:
-Dorg.apache.myfaces.trinidad.CHECK_STATE_SERIALIZATION=all
Note that this check is disabled by default to reduce runtime overhead. Do not use this after your testing is complete.
-> Changes in ADF code
-> Please make sure that managed beans used in ADF application with a scope greater than one request should be serializable ( implement the java.io.Serializable interface). Specifically, beans stored in session scope, page flow scope, and view scope need to be serializable.
– All pageflowscope and viewscope managed beans should not contain UI bindings. In essence, component bindings should live for a http request (request scope or backingBean scope). Any state or data you need for a longer duration can be saved in a pageflowscope bean separately.
– Make sure Oracle ADF is aware of changes to managed beans stored in ADF scopes (view scope and page flow scope) and enable the tracking of changes to ADF memory scopes.
use below code to notify ADF
controllerContext ctx = ControllerContext.getInstance(); ctx.markScopeDirty(viewScope);
-> Configuring Application Modules
– Right-click the application module and select Configurations.Click Edit.Click the Pooling and Scalability tab.
Select the Failover Transaction State Upon Managed Release checkbox.
<AppModuleConfig ... <AM-Pooling jbo.dofailover="true"/> </AppModuleConfig>
-> Configuring weblogic.xml
In weblogic.xml file, add entry as below persistent-store-type definition to the session-descriptor element like below
<weblogic-web-app>
<session-descriptor>
<persistent-store-type>
replicated_if_clustered
</persistent-store-type>
</session-descriptor>
</weblogic-web-app>
-> Configuring adf-config.xml
In adf-config.xml file, add entry as like below
<adf-controller-config xmlns="http://xmlns.oracle.com/adf/controller/config"> <adf-scope-ha-support>true</adf-scope-ha-support> </adf-controller-config>
Happy Learning with Vinay In techartifact.
Ref- http://docs.oracle.com/cd/E12839_01/core.1111/e10106/adf.htm