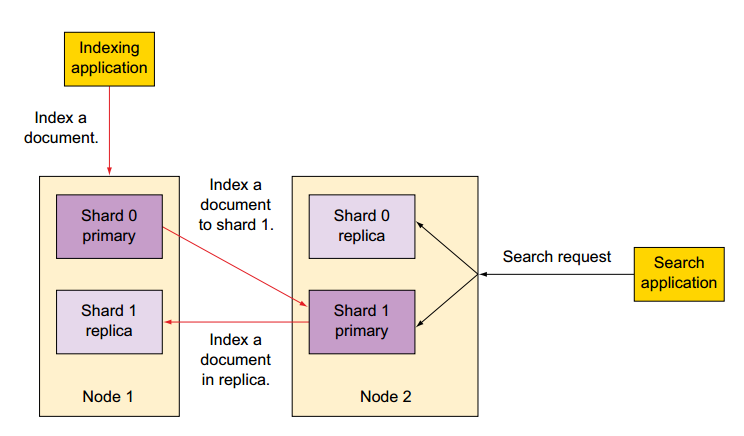
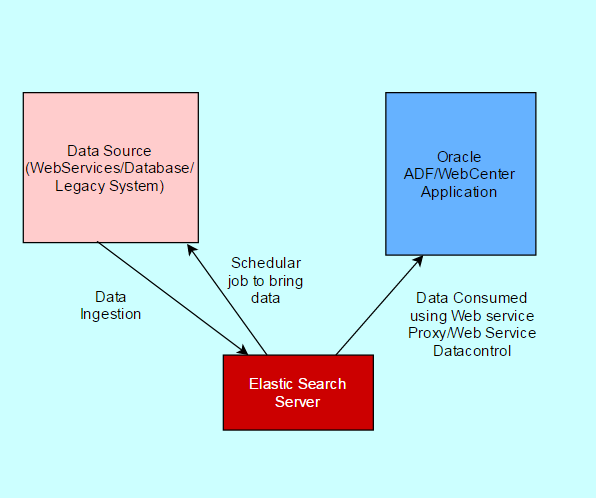
Oracle Platform Security Services (OPSS) provides enterprise product development teams, systems integrators (SIs), and independent software vendors (ISVs) with a standards-based, portable, integrated, enterprise-grade security framework for Java Standard Edition (Java SE) and Java Enterprise Edition (Java EE) applications.
OPSS provides an abstraction layer in the form of standards-based application programming interfaces (APIs) that insulate developers from security and identity management implementation details. With OPSS, developers don’t need to know the details of cryptographic key management or interfaces with user repositories and other identity management infrastructures. Thanks to OPSS, in-house developed applications, third-party applications, and integrated applications benefit from the same, uniform security, identity management, and audit services across the enterprise.
OPSS is the underlying security platform that provides security to Oracle Fusion Middleware including products like WebLogic Server, SOA, WebCenter, ADF, OES to name a few. OPSS is designed from the ground up to be portable to third-party application servers. As a result, developers can use OPSS as the single security framework for both Oracle and third-party environments, thus decreasing application development, administration, and maintenance costs.
Products which use OPSS
-
Oracle WebLogic Server
-
Oracle ADF
-
Oracle WebCenter
-
Oracle SOA
-
Oracle Entitlement server
-
Oracle WebService Manager
-
Java Authorization for Containers (JAAC)
OPSS provides an integrated security platform that supports:
-
Authentication
-
Identity assertion
-
Authorization, based on fine-grained JAAS permissions
-
The specification and management of application policies
-
Secure storage and access of system credentials through the Credential Store Framework
-
Auditing
-
Role administration and role mappings
-
The User and Role API
-
Identity Virtualization
-
Security configuration and management
-
SAML and XACML
-
Oracle Security Developer Tools, including cryptography tools
-
Policy Management API
-
Java Authorization for Containers (JAAC)
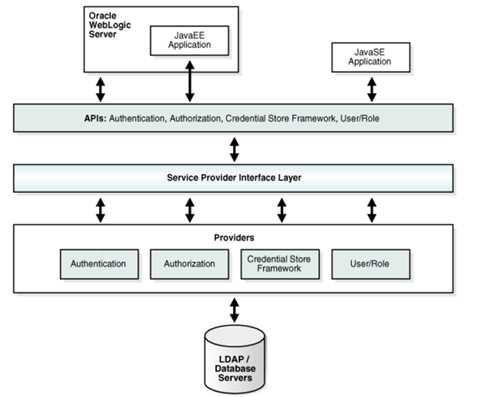
OPSS Architecture
Now moving further with use of OPSS with ADF/WebCenter application. We have features , so that user can search user from LDAP using name, last name or email. How can we achieve that.
Something like below image.
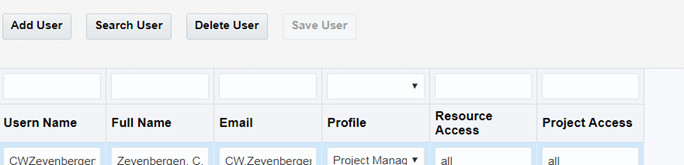
User click on Search User-This will search in Active directory user mapped with WebLogic security provider.
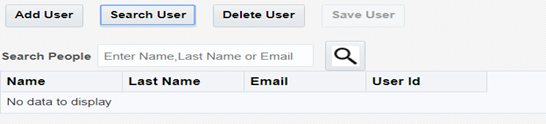
In Search box, enter Name, Last Name or email and click on Search icon .
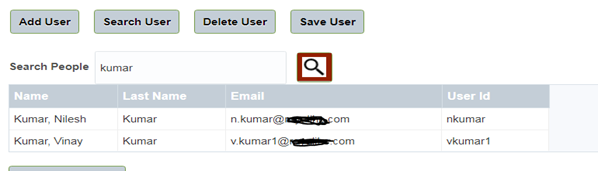
Or try with email
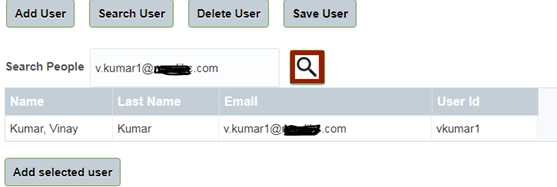
So you can add some more custom parameters with that and search it. Now we will focus how we did that.
Following is code to search with parameter in OPSS
public List<userProfileId> getUserDetails() {
if (this.userDetails.size() == 0) {
if (peopleName != null) {
try {
JpsContextFactory ctxFactory = JpsContextFactory.getContextFactory();
JpsContext ctx = ctxFactory.getContext();
LdapIdentityStore idstoreService =
(LdapIdentityStore) ctx.getServiceInstance(IdentityStoreService.class);
IdentityStore idmIdentityStore = idstoreService.getIdmStore();
// User user = idmIdentityStore.searchUser(peopleName.getValue().toString());
if (peopleName.getValue() != null) {
SimpleSearchFilter simpleSearchFilter[] = new SimpleSearchFilter[3];
simpleSearchFilter[0] =
idmIdentityStore.getSimpleSearchFilter(UserProfile.LAST_NAME, SimpleSearchFilter.TYPE_EQUAL,
peopleName.getValue().toString());
simpleSearchFilter[1] =
idmIdentityStore.getSimpleSearchFilter(UserProfile.BUSINESS_EMAIL,
SimpleSearchFilter.TYPE_EQUAL,
peopleName.getValue().toString());
simpleSearchFilter[2] =
idmIdentityStore.getSimpleSearchFilter(UserProfile.NAME, SimpleSearchFilter.TYPE_EQUAL,
peopleName.getValue().toString());
ComplexSearchFilter cf =
idmIdentityStore.getComplexSearchFilter(simpleSearchFilter, ComplexSearchFilter.TYPE_OR);
/* Creating Search Parameters with Complex Search Filters */
SearchParameters spUser = new SearchParameters(cf, SearchParameters.SEARCH_USERS_ONLY);
SearchResponse searchResponse = idmIdentityStore.searchUsers(spUser);
while (searchResponse.hasNext()) {
System.out.println("Count " + searchResponse.getResultCount());
UserProfile up = (UserProfile) searchResponse.next();
System.out.println("User Profile:" + up.getPrincipal());
name = up.getName();
email = up.getBusinessEmail();
UserID = up.getLastName();
UserName = up.getUserName();
userDetails.add(new userProfileId(name, UserID, email, UserName));
}
}
// uprofile.setUserDetailss(userDetails);
/* UserProfile up = user.getUserProfile();*/
} catch (JpsException e) {
e.printStackTrace();
System.out.println(e);
} catch (IMException e) {
System.out.println(e);
} catch (Exception e) {
System.out.println(e);
}
}
}
return userDetails;
}
That’s it. You can use this following ocde in pure ADF or WebCenter Portal applications easily. Do let me know your thoughts.
Happy Learning with Techartifact.